Data Management on Legion
Legion Filestores
Legion topology:
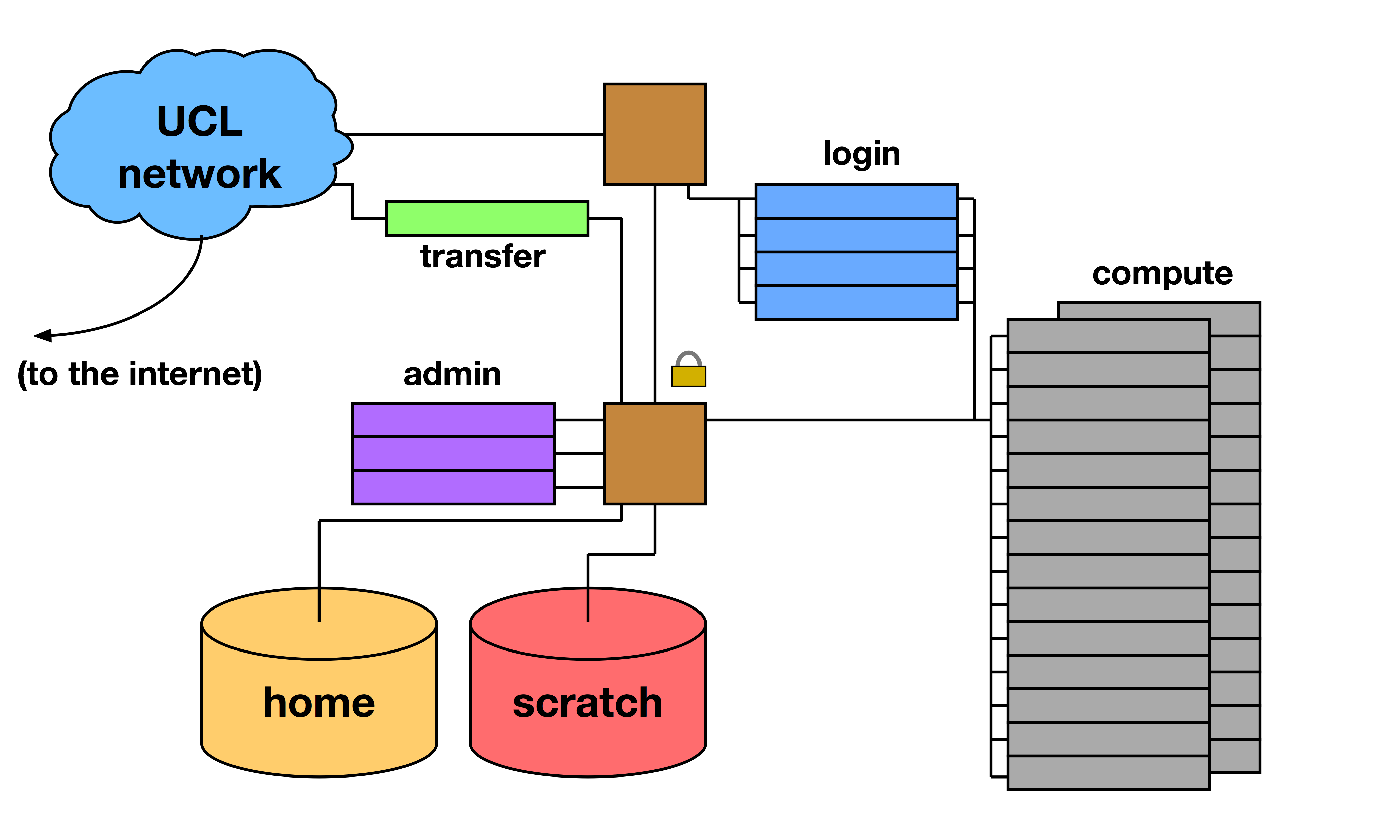
The Legion Cluster has two main filestores home and Scratch.
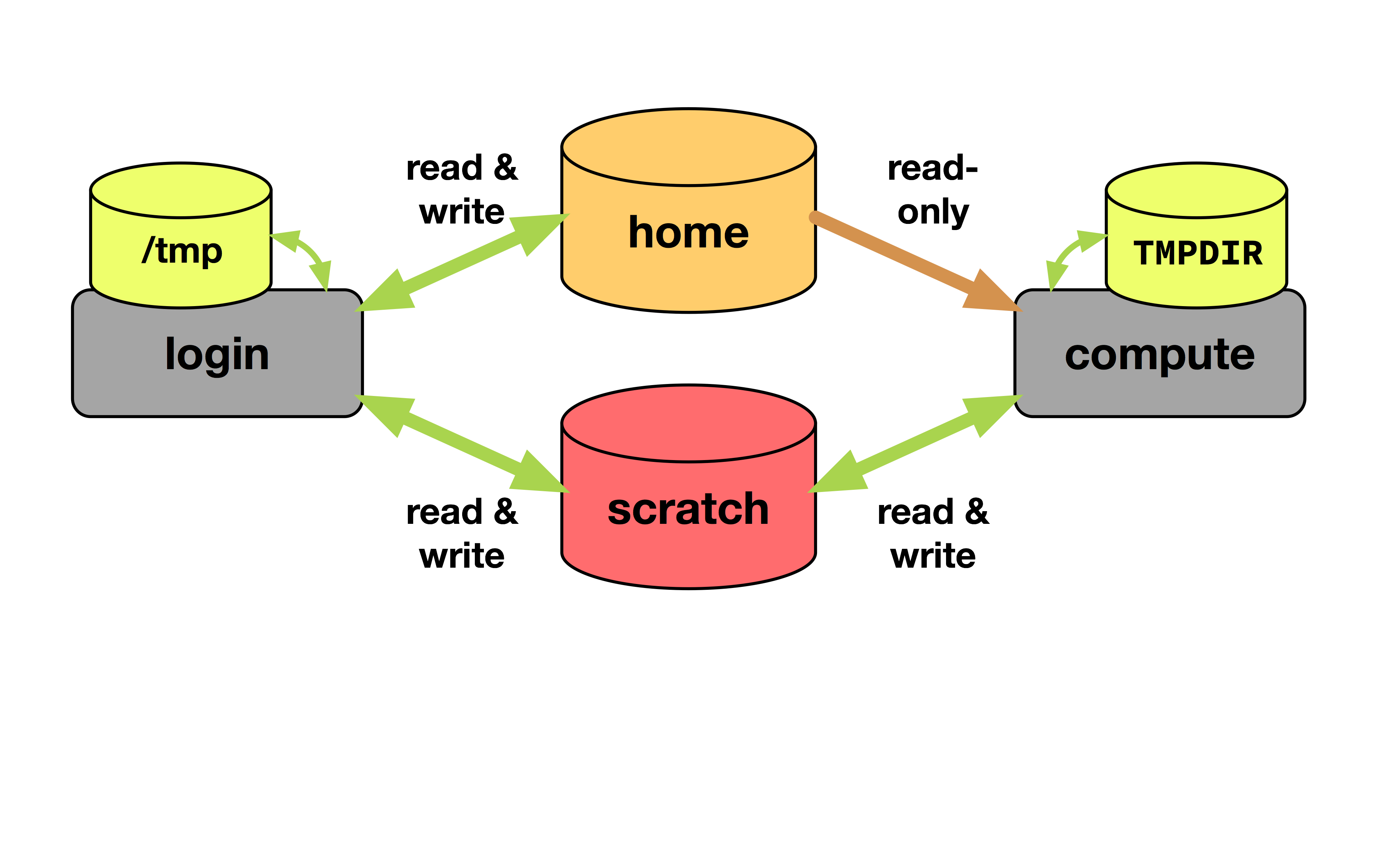
Home directories ($HOME)
This is your primary filestore.
- Small amount of storage
- Backed up
- Read-only access from compute nodes
This storage has currently a hard quota of 50GB per user. It is the most reliable. But due to contention between several users it has very high performance variability.
You can read and write to it from the login nodes, but only read access is granted from the compute nodes.
The rationale for this stems from the fact that it cannot withstand large amounts of Input/Output such as that which happens within a large cluster like Legion. This is also to make sure that only important data is backed up as otherwise there would be excessive load on the backup system both in terms of performance and capacity.
Shared scratch area ($HOME/Scratch)
This is where the output from your Legion jobs are stored.
There is no guarantee that data stored on this file system is safe and strongly recommend that you save any important data as soon as possible to your $HOME directory via login nodes or any other external backup storage.
- More storage than $HOME
- Not backed up
- Writable by compute nodes
~/Scratchis a shortcut to/scratch/scratch/$USER
The use of Scratch is subject to the following policies:
-
All users will be granted an initial Scratch quota. Users are free to work within this quota but should note that files stored in their Scratch directory are NOT backed up and should therefore be considered ‘at risk’.
-
Users may request increases in their Scratch quota by submitting a form to rc-support@ucl.ac.uk. They will be required to explain why they need an increase from a technical and computational point of view.
-
The Scratch quota will be implemented as a soft quota so users will be able to temporarily exceed their quota for a short period.
-
When a user exceeds their Scratch quota a warning is added to their Legion Message of the Day (MOTD) and an email is sent to their UCL email address. The warnings will display how much they are over quota, how long they have to reduce their usage and what will happen if they fail to reduce their usage.
-
While a user continues to use more than their Scratch quota subsequent warning emails will be sent by the system every day.
-
If a user reduces their usage of Scratch to below their quota within the grace period, no further action will be taken.
-
At the end of the grace period if a user hasn’t reduced their Scratch usage to below their quota, the system will stop the user from submitting any jobs until their Scratch usage is below their quota.
Local node scratch area ($TMPDIR)
- Only exists during your job
- Fastest access as is local
This storage resides on the hard drive installed in the compute nodes. It is only accessible temporarily throughout the duration of the job you have submitted and only within each of the compute nodes assigned to you. The path to this storage is set at run time in the $TMPDIR environment variable.
This variable is set only within a shell generated by the SGE scheduler, and the path therein is unique to the node and job you are running. Once your job has completed the $TMPDIR directory is deleted on each node, so make sure that you have given enough wall clock time to allow data to be transferred back to your scratch area.
Note that in parallel jobs running N slots (processes) only the main node ( slot 1 ) can be scripted as the remaining N-1 ones are just used to run compute processes without shell interaction - this means that your parallel program should only write to this local storage on process 1 (or 0, depending on the programming language). Users may automate the transfer of data from $TMPDIR to their scratch area by adding the directive #Local2Scratch to their job script.
The amount of space available in $TMPDIR is controlled on a per node basis by the #$ -l tmpfs grid engine directive. This is to stop jobs interfering with each other by running out of disk space. If this directive is omitted from job scripts, then a default of 10 Gigabytes per node will be allocated to the job. For example to request 15 GB include:
#$ -l tmpfs=15G
in the job script.