Shared-Variable Parallelism vs Message-Passing Parallelism
So far we have explained what is meant but parallelism and introduced some constraints to its use (Amdahl’s Law). We will now discuss two types of parallelism: Shared-Variable and Message-Passing.
Shared-Variable Parallelism
We have predominantly spoken so far about processes. Shared-Variable parallelism makes use of threads, so, what are threads?
Threads
Threads are sub-components of a process. The Georgia Tech video “Difference Between Process and Thread” explains what threads are how they relate to processes:
The transcript can be viewed by clicking on ‘…More’ then ‘Transcript’ on the YouTube page: https://www.youtube.com/watch?v=O3EyzlZxx3g
Note that although threads can run on different cores, they can only run within the same node.
Shared memory
As you will have seen in the video, threads make use of shared memory. This means that synchronisation is very important between threads, especially when one thread is dependent on data updated by another.
Analogy (taken from http://www.archer.ac.uk/training/course-material/2016/07/intro_epcc/slides/L08_ParallelModels.pdf)
Imagine a large whiteboard in a two-person office, this is the shared memory.
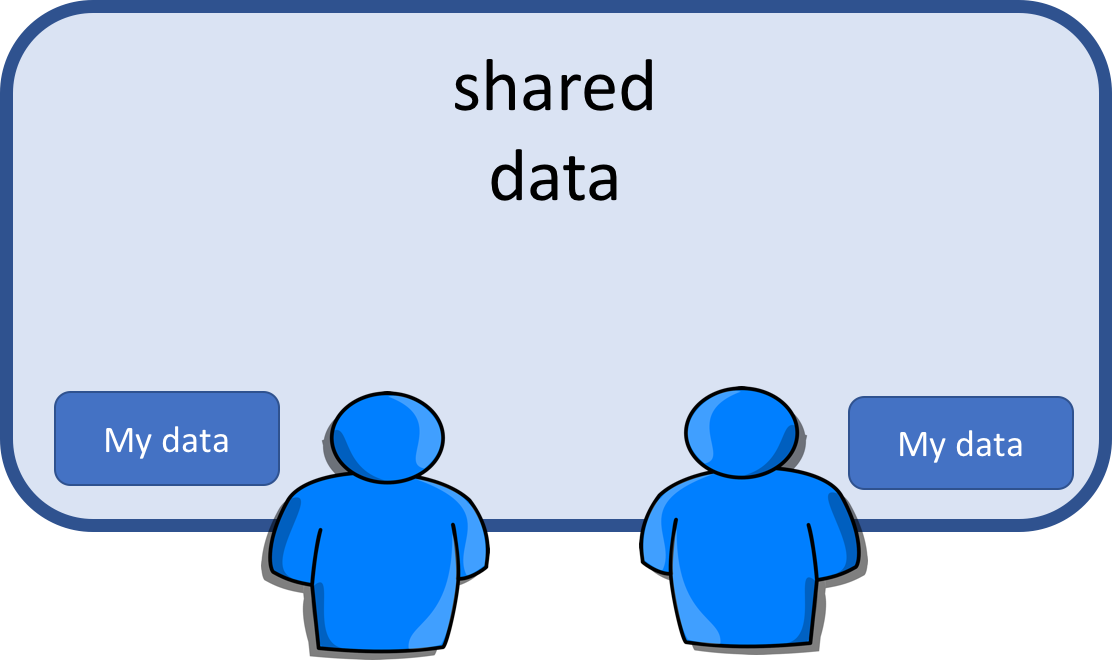
Two people working on the same problem, the threads running on different cores attached to the memory.
How do they collaborate?
- working together
- but not interfering
Also need private data.
Threads in HPC
- For parallel computing we typically run a single thread per core with the aim of wanting them all to run, all of the time.
- Controlled by a single operating system.
- Requires a shared memory architecture and cannot scale beyond a single node.
- The threads operate independently on the shared data, synchronisation is crucial to ensure that they do not interfere with each other.
Shared memory architecture:
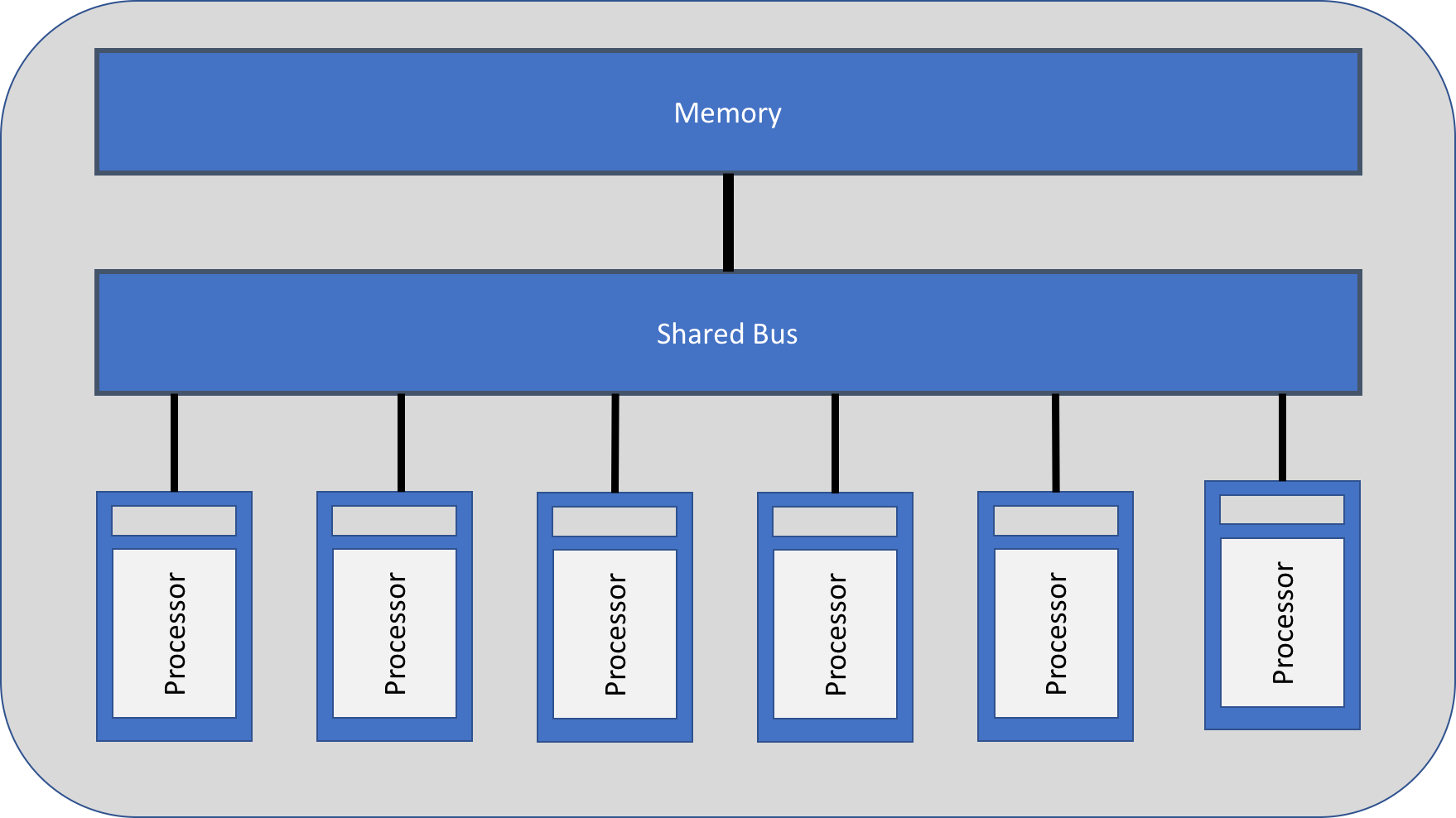
Message-Passing Parallelism
Process-based parallelism. Uses distributed memory.
Analogy (taken from http://www.archer.ac.uk/training/course-material/2016/07/intro_epcc/slides/L08_ParallelModels.pdf)
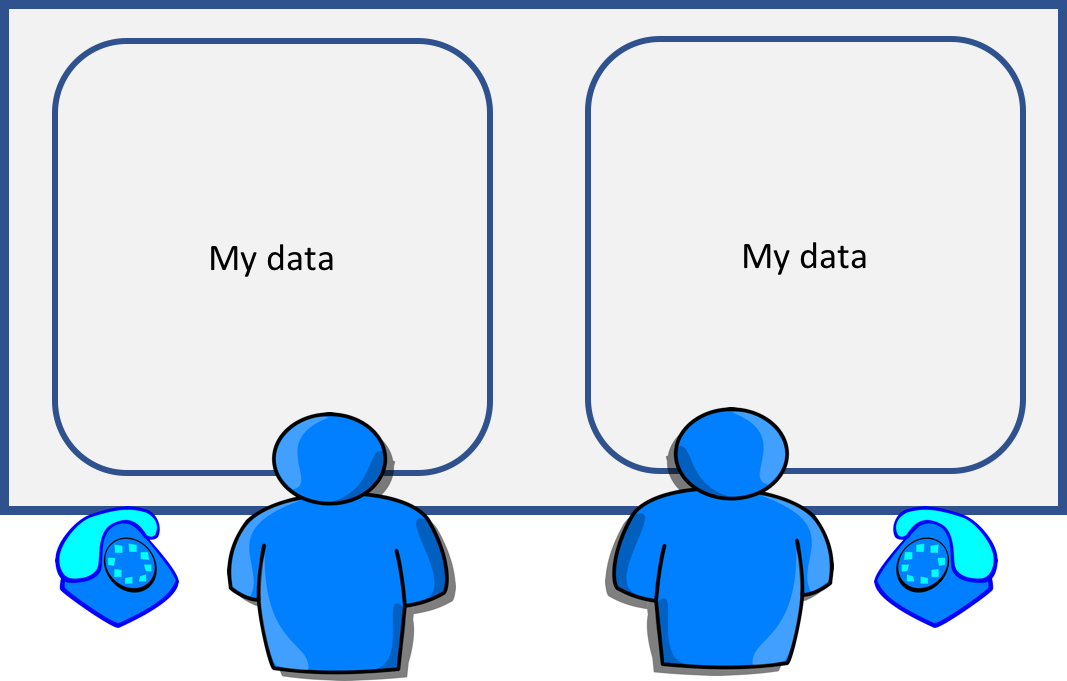
Imagine two single person offices, with a whiteboard in each office. This is the distributed memory.
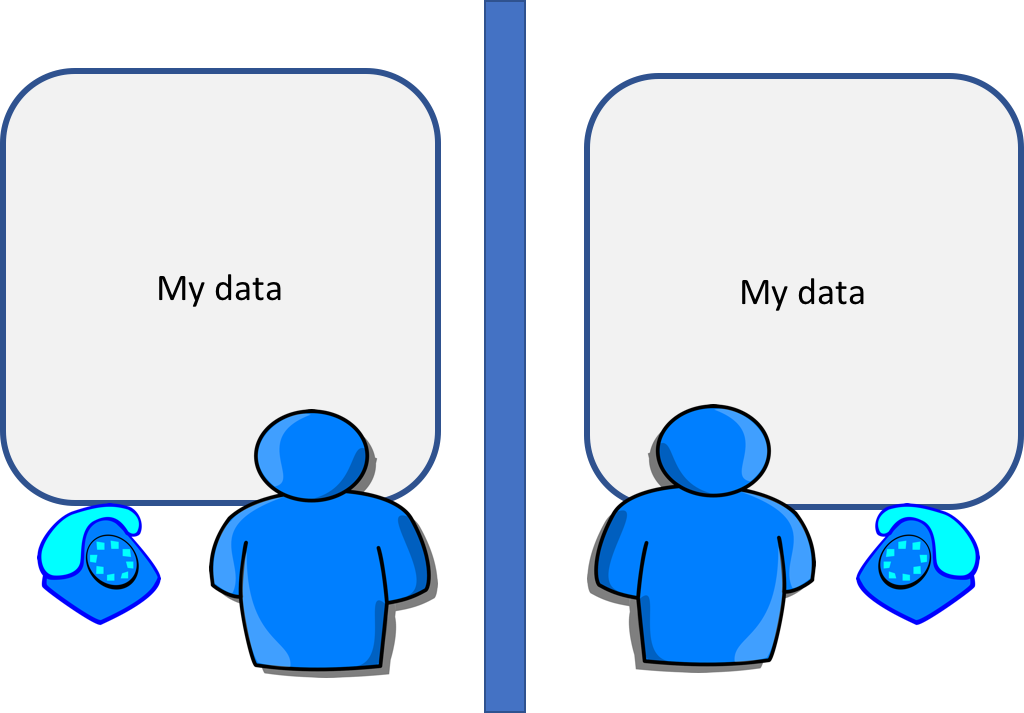
Two people working on the same problem, the processes on the different nodes attached to the interconnect(connection between nodes).
How do they collaborate?
- work on a single problem
- explicit communication e.g. by telephone
- make a phone call …
- … wait until the receiver picks up
- receive a phone call …
- … wait until the phone rings
- make a phone call …
- no data shared so no risk of corrupting someone else’s data or having your own corrupted
Synchronisation
Unlike threads, synchronisation happens automatically as part of the message passing process.
Message sending can be either synchronous or asynchronous.
Synchronous send:
- not completed until the message has started to be received.
Asynchronous send:
- completes as soon as the message has gone.
Receives are usually synchronous, the receiving process must wait until the message arrives.
Communications
If we have two processes; one sender and one receiver, this is known as point-to-point communication. This is the simplest form of message passing and relies on matching send and receive.
Often however, we need to communicate between groups of processes. This is known as collective communications. This can take the form of a broadcast to all message.
Distributed memory architecture:
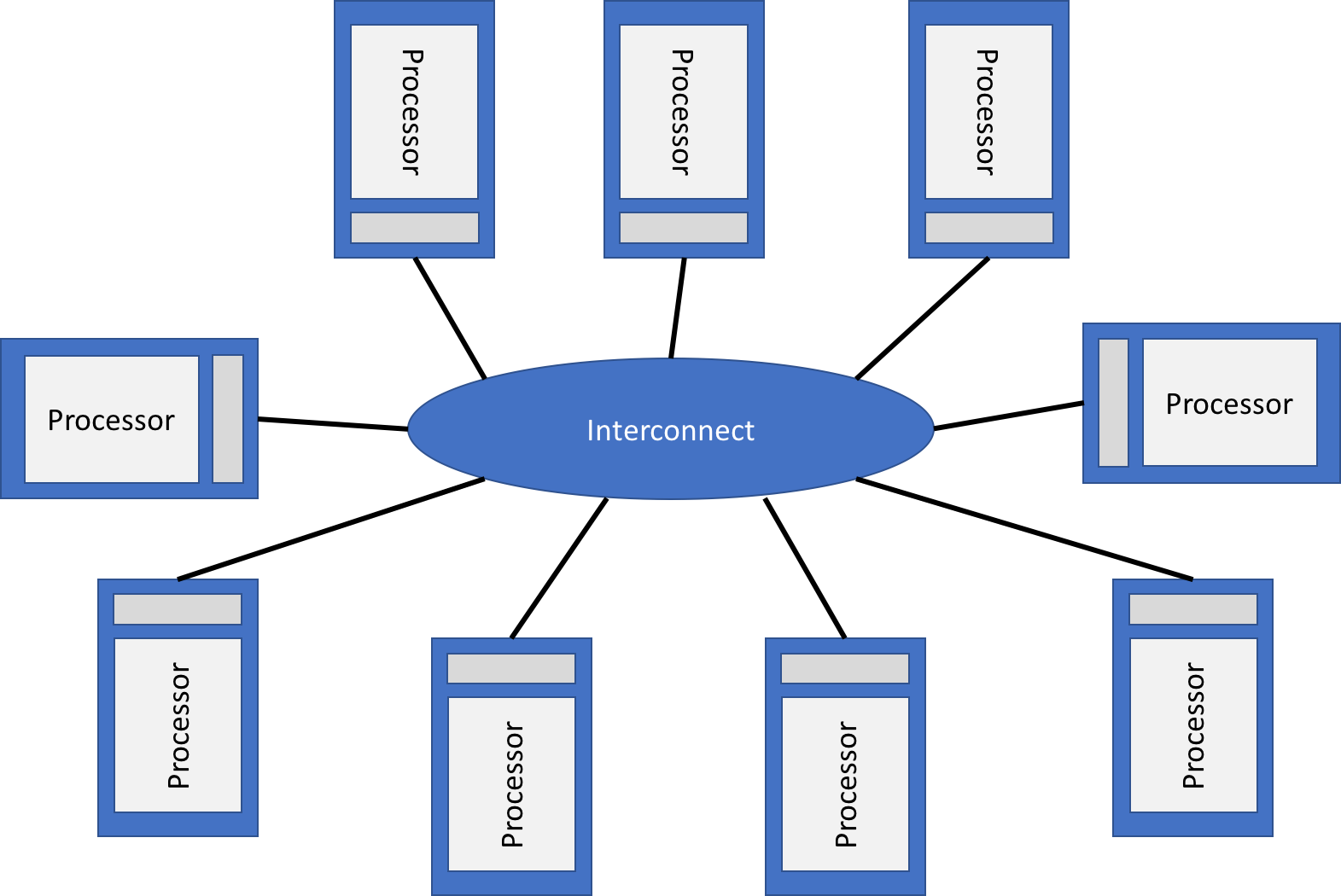
Message passing on shared memory
One process runs on each core and does not directly exploit shared memory. Analogous to phoning a colleague in the same office.
Message-passing programs are run by a special job launcher. The user specifies the number of copies and there is some control over allocation to nodes.
Summary
- Processes are ring-fenced from one another, and are therefore unable to share memory.
- Communication requires explicit messages, analogous to making a phone call or sending an email.
- Synchronisation is done by the messages.
- Message-Passing Interface (MPI), a library of function calls/sub-routines, is almost exclusively used for this.